Humanoid Robot Masters Arm Control With Tiny AI Model
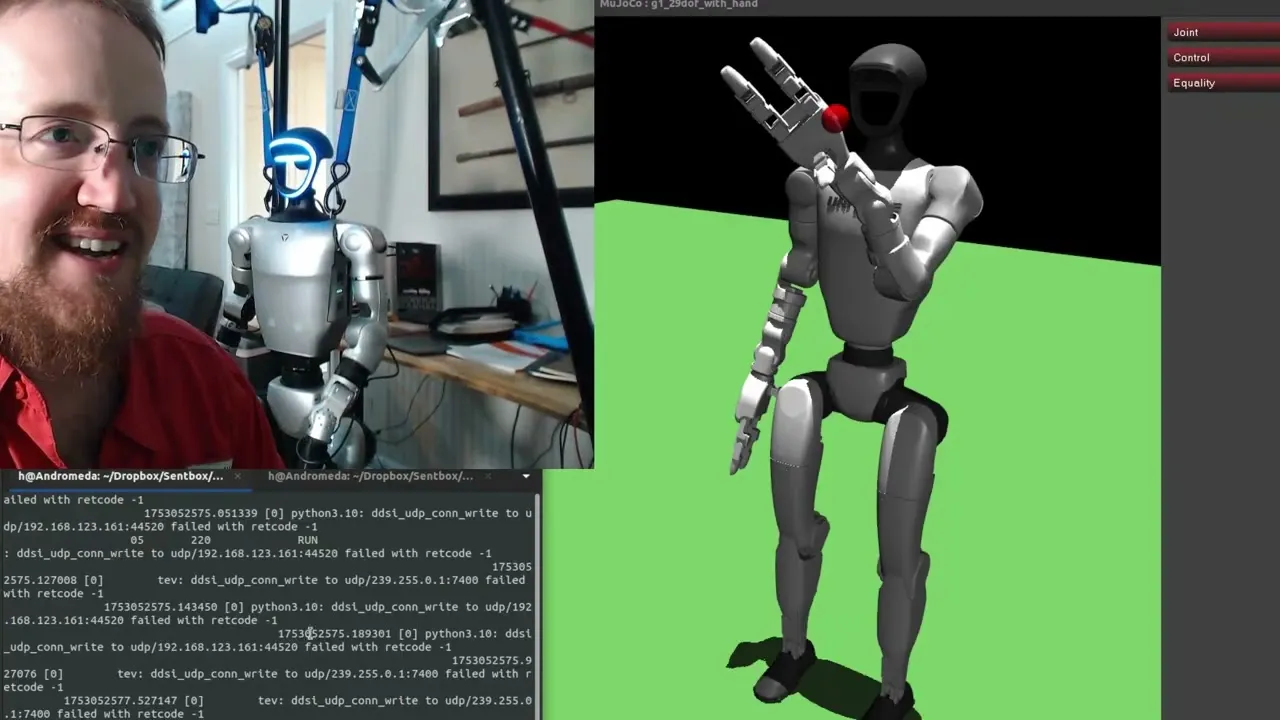
A recent demonstration showcases a Unitree G1 humanoid robot successfully executing complex arm movements controlled by a remarkably small reinforcement learning (RL) model. This breakthrough, achieved with a model file measuring just 184 kilobytes, highlights the potential for efficient AI integration in robotics, allowing for precise manipulation tasks previously requiring much larger computational resources.
Reinforcement Learning Powers Dexterous Manipulation
The core of this advancement lies in a reinforcement learning policy developed using Proximal Policy Optimization (PPO), a well-regarded algorithm in the field. The AI model, described as a “2×64 model,” was trained to control the robot’s arm, aiming to reach a designated target position in three-dimensional space. The user can manually control this target using keyboard inputs (up, down, left, right, forward, back), effectively commanding the robot’s hand position.
This approach bypasses the need for complex computer vision or sensor fusion in its current state. Instead, the RL policy directly maps the robot’s current arm joint positions and velocities, along with the target coordinates, to a series of incremental joint commands. This allows the robot’s arm to dynamically adjust and move towards the specified goal, demonstrating a fundamental capability for grasping and manipulation.
Sim-to-Real Transfer and Performance
A critical aspect of this demonstration is the successful transfer of the learned policy from a simulated environment to the physical Unitree G1 robot. The developer emphasized the importance of ensuring the simulated robot’s joint mapping and physical characteristics closely mirrored the real-world counterpart. While acknowledging that the sim-to-real transfer isn’t “perfect,” the results suggest it was sufficiently accurate for the arm control task.
The performance of the RL policy was impressive, with the robot’s arm smoothly tracking the target. Initially, the movements were deliberately slow for safety, as the robot possesses the capability for much faster actions.
However, the developer later demonstrated increased speed, showing the robot responding more rapidly to target changes. Even at accelerated speeds, the arm maintained its objective, though increased speed did introduce new challenges, such as the arm entering a state where it would “give up” if a motor struggled for too long, necessitating a robot reboot.
Challenges and Future Directions
Despite the success, the developer highlighted several areas for improvement and ongoing challenges. One significant hurdle was achieving a specific hand orientation for grasping.
The initial goal was for the hand to be parallel to the ground with fingers perpendicular, facilitating bottle grabbing. While some regularization was added to incentivize this, the RL policy did not consistently achieve this pose, indicating that further training or adjustments to the reward function are needed.
The developer also discussed the limitations of the current setup, including the need to manually control the target position. Future iterations aim to incorporate camera input, lidar, or depth sensors to allow the robot to perceive and react to its environment autonomously.
Another observed issue was the robot’s tendency to enter a “damp” or unresponsive state if a joint limit was repeatedly pushed, sometimes requiring a full reboot. This points to the need for more robust error handling and potentially more constrained joint limits within the RL training process.
Technical Details and Model Architecture
The observation space for the RL model consists of 24 values, including seven joint angles, seven joint velocities, the hand’s XYZ position, the target XYZ position, the delta vector between current and target positions, and a step fraction for the episode. The action space is simpler, a 7-dimensional vector dictating incremental joint commands for each of the seven arm joints.
The PPO algorithm, implemented using the Stable Baselines3 library, was chosen for its reliability and ease of training in robotics. The small model size is attributed to the “2×64” architecture, resulting in a highly efficient policy that can be loaded quickly onto the robot. The training process itself took approximately 24 hours, with the developer planning to improve multiprocessing capabilities for faster and more extensive training runs.
The reward function is crucial for shaping the AI’s behavior. It provides positive rewards for reaching the target within a 2 cm tolerance, negative rewards for collisions or hitting joint limits, and a penalty for the episode taking too long. The developer is exploring additional constraints, such as limiting extreme elbow bends or excessive rotation in certain joints, to prevent the arm from entering problematic states and to encourage more natural, less contorted movements.
Why This Matters
This development is significant for several reasons. Firstly, it demonstrates that highly capable robotic control can be achieved with surprisingly small and efficient AI models. This has profound implications for deploying AI on robots with limited onboard processing power or battery life.
Secondly, the successful sim-to-real transfer, even with minor imperfections, showcases the growing maturity of RL techniques for real-world robotic applications. As RL models become more sophisticated and easier to train, robots will gain enhanced dexterity and adaptability for tasks ranging from industrial automation and logistics to assistive care and exploration.
The ability to control a complex robotic arm with such a compact model suggests a path towards more accessible and customizable robotic solutions. The open-sourcing of the code and models on GitHub further empowers the robotics community to build upon this work, accelerating innovation in the field.
Availability and Code
The developer has made the code and trained models available on a GitHub repository, specifically within the “RL shenanigans” directory. Users are advised that the repository is expected to be a “big mess” due to ongoing development.
Modifications to the Unitree SDK may be required. The developer encourages community contributions, inviting others to share their trained models and provide feedback.
Source: Reinforcement learning with Unitree G1 humanoid – Dev w/ G1 P.5 (YouTube)