Free Transformer Unlocks Latent Variables for Smarter AI
Researchers are pushing the boundaries of artificial intelligence with novel architectures designed to imbue models with a deeper understanding of data. One such advancement is the ‘Free Transformer,’ a novel architecture emerging from France, which aims to enhance traditional transformer models by incorporating latent variables. These latent variables act as hidden decision-makers, guiding the generation process and potentially leading to more coherent and controllable AI outputs.
The Limitations of Traditional Transformers
Fundamentally, a transformer model operates by processing sequences of data, such as text. When generating new sequences, like writing a movie review based on a movie description, standard transformers rely on a probabilistic sampling process at each step. For instance, if a model is trained on movie reviews, it learns that for a good movie, most reviews will be positive, but some might still be negative.
A traditional transformer, when prompted, will generate a review by predicting the most likely next word (token) based on the preceding ones. Randomness is introduced only at the final token sampling stage.
This means that the model’s output, whether it’s a positive or negative review, is determined by a series of these probabilistic choices. While large models with sufficient data can learn to generate outputs in the correct proportions (e.g., 90% positive reviews for a good movie), the underlying ‘decision’ to lean positive or negative emerges organically from the sequence of token predictions.
The challenge lies in how this decision is made. In a movie review scenario, if the model samples a token that strongly suggests a positive review, subsequent tokens must remain consistent with that sentiment. Conversely, if a negative-leaning token is sampled, the rest of the review will likely follow suit.
This incremental, token-by-token decision-making can be complex. The paper posits that it would be more efficient and controllable if a higher-level ‘decision’ or ‘latent variable’ were made upfront, influencing the entire generation process from the start.
Introducing Latent Variables
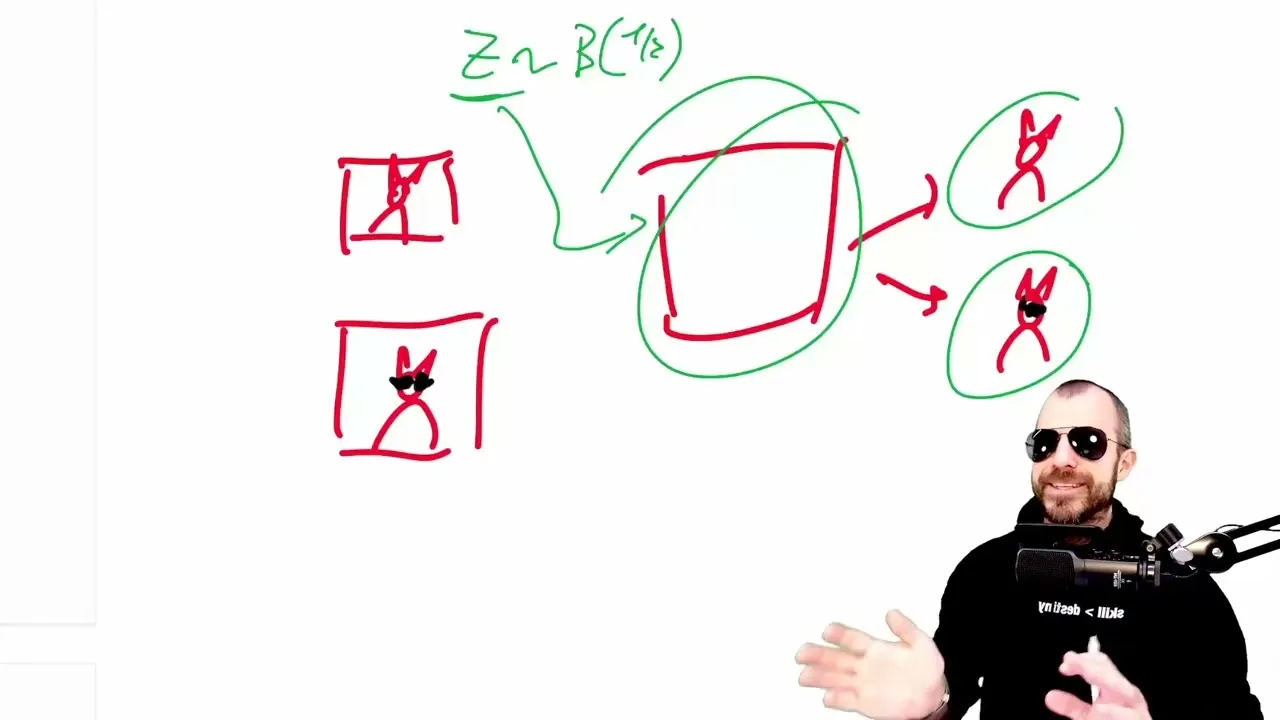
The Free Transformer proposes to inject these explicit latent variables into the transformer architecture. Imagine wanting to generate a movie review. Instead of the model figuring out whether to write a good or bad review purely through token sampling, a latent variable could be introduced at the beginning, explicitly stating ‘generate a good review.’ This variable would then inform every subsequent token generation, ensuring consistency and potentially simplifying the model’s task.
The paper uses the analogy of generating images of cats, where a latent variable could dictate whether the cat wears sunglasses or not. This upfront decision, guided by a latent variable, is argued to be more efficient than relying on the probabilistic sampling of tokens to eventually converge on the desired outcome.
The Role of Variational Autoencoders (VAEs)
To manage these latent variables, especially when they are not explicitly provided during training, the Free Transformer draws inspiration from Variational Autoencoders (VAEs). VAEs are a type of generative model that learns to encode data into a compressed latent space and then decode it back.
The key innovation in VAEs, relevant here, is their ability to learn these latent representations even without direct labels for them. In the cat example, a VAE might learn that a particular dimension in its latent space corresponds to the presence or absence of sunglasses, even if the training data only consists of cat images and their descriptions.
The Free Transformer integrates a VAE-like mechanism. During training, an ‘encoder’ component, which can ‘cheat’ by looking ahead at the entire sequence to be generated, maps the data into a latent variable (Z). This Z is then fed to the transformer’s ‘decoder’ alongside the usual token inputs.
The training process includes a reconstruction loss (ensuring the output matches the input) and a regularization term (KL divergence) that forces the learned latent variables to conform to a desired prior distribution (e.g., a standard normal distribution). This regularization is crucial: it ensures that during inference, when a Z is sampled from this prior distribution, the decoder can still produce meaningful outputs because it has been trained to associate Zs from this distribution with specific outcomes.
Architecture and Efficiency
The Free Transformer isn’t necessarily a completely new model but rather a modification of existing transformer architectures. The paper suggests ways to integrate this VAE-like component efficiently. One approach involves splitting the transformer into two parts, with a small, non-causal encoder block placed in the middle.
This encoder leverages the outputs from the initial transformer blocks to derive the latent variables. This placement is strategic: putting it too early might not give the encoder enough information to work with, while putting it too late might not allow the decoder sufficient layers to effectively utilize the latent variables. By sharing computation between the encoder and decoder, this design aims to be more resource-conscious than using entirely separate models.
During training, the encoder gets to see the full sequence, allowing it to learn meaningful latent representations. During inference, however, only a Z is sampled from a predefined distribution, and the decoder uses this sampled Z along with the standard autoregressive process to generate output. This allows for controlled generation, where the sampled Z can guide the output’s characteristics.
Experimental Findings and Implications
Experiments on synthetic data illustrated the delicate balance required. If too little information is passed through the latent variable, it fails to capture the necessary data characteristics.
Conversely, if too much information is allowed, the decoder becomes overly reliant on the encoder’s ‘cheating’ during training and fails to learn independently, leading to poor performance during inference. The ‘sweet spot’ is when the latent variable effectively captures key underlying factors, such as the position of a specific pattern in a sequence, enabling the decoder to utilize this information for consistent generation.
While the Free Transformer shows promise, particularly in areas like coding and mathematics, it reportedly does not perform as strongly in tasks like question answering or knowledge retrieval. The authors acknowledge that the success of this approach hinges on careful hyperparameter tuning and managing the trade-offs inherent in information flow between the encoder and decoder. Whether this architectural innovation becomes a mainstream hit in the large language model landscape remains to be seen, but it represents a significant step in exploring more structured and controllable generative AI.
Why This Matters
The Free Transformer’s core contribution is its attempt to explicitly model and control the underlying factors that influence AI generation. By introducing latent variables, it offers a potential path toward more interpretable and controllable AI. Instead of a black box making probabilistic guesses token by token, this architecture allows for higher-level concepts to guide the generation.
This could lead to AI systems that are not only more coherent but also more predictable and easier to steer towards specific desired outputs. For applications ranging from creative writing to scientific simulation, the ability to inject and control these latent ‘decisions’ could unlock new levels of performance and utility.
Source: [Paper Analysis] The Free Transformer (and some Variational Autoencoder stuff) (YouTube)



