AI Retrieval Hits Theoretical Wall: Random Data Limitations Exposed
A new academic paper is challenging fundamental assumptions about how Artificial Intelligence systems retrieve information, particularly those relying on embedding-based methods. While the findings are largely theoretical and focus on ‘random data,’ they highlight inherent limitations in representing complex relationships, sparking debate about current AI expectations.
Understanding Embedding-Based Retrieval
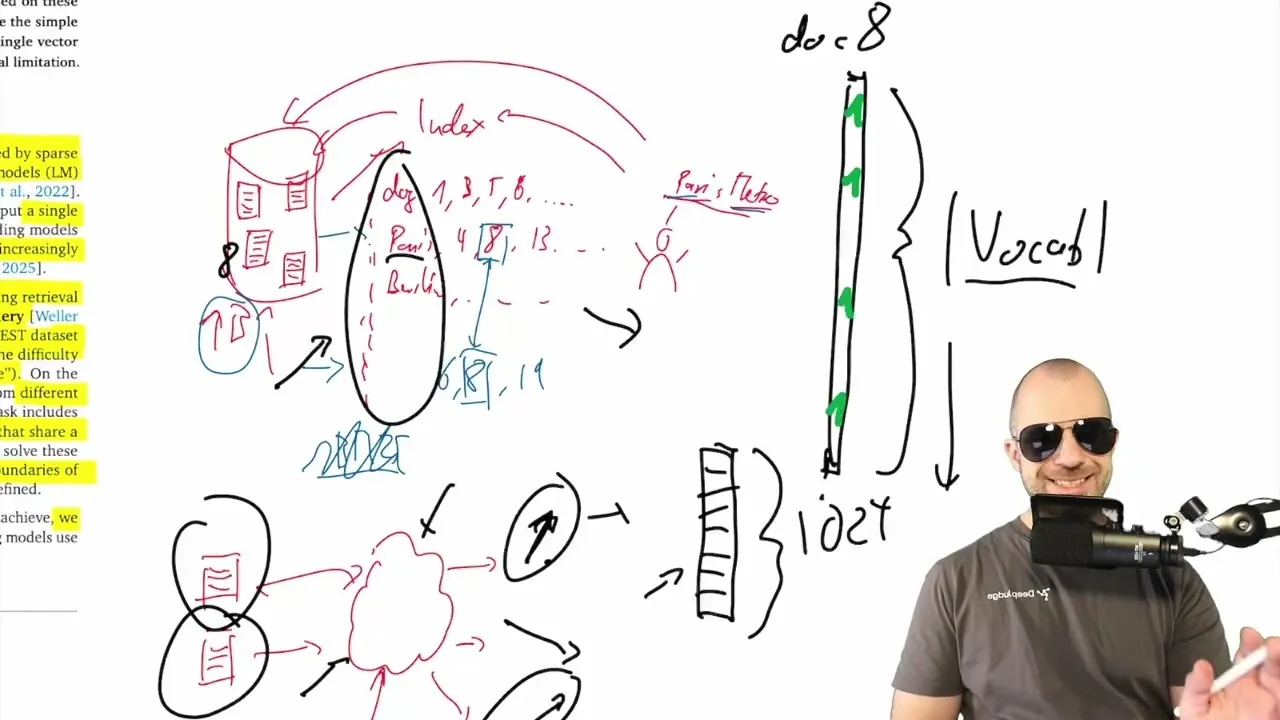
Fundamentally, information retrieval is about finding relevant data from a vast collection. Traditionally, this involved building indexes like those found at the back of books, mapping words to the documents they appear in. Search engines would then use techniques like reverse lookups and intersection to find matching documents for a query.
The modern approach, embedding-based retrieval, takes a different tack. Instead of keywords, documents and queries are converted into dense numerical vectors, often called embeddings, using neural networks. The idea is that vectors pointing in similar directions represent semantically related content.
When a query’s vector is close to a document’s vector, it’s considered a relevant match. This is the backbone of many current AI applications, including Retrieval-Augmented Generation (RAG) systems.
The Paper’s Core Argument: Limitations with Random Data
The paper, titled “On the Theoretical Limitations of Embedding-Based Retrieval,” digs into the mathematical underpinnings of these vector representations. Its central thesis, according to the analysis, is that while embedding models are powerful, they struggle with representing truly arbitrary combinations of data, especially when that data lacks inherent structure.
The researchers argue that the expectation that embedding vectors alone can perfectly handle increasingly complex retrieval tasks, including those requiring logical reasoning or arbitrary instruction following, is too high. They introduce the concept of ‘sign rank,’ a measure related to the complexity of relationships within data that can be represented by embeddings. A higher sign rank indicates more complex relationships, which in turn requires a higher embedding dimension.
The paper’s key finding is that for any fixed embedding dimension, there will always exist combinations of data (specifically, pairs of documents) that cannot be perfectly retrieved. This is because the embedding process, by its nature, compresses information and sacrifices the ability to represent every single possible combination in favor of capturing underlying structure.
The authors mathematically prove that as the complexity of potential relationships increases (i.e., the ‘sign rank’ of the relevance matrix), the required embedding dimension also increases. Ultimately, for any given dimension, there’s a limit to the complexity of arbitrary relationships that can be captured.
Why This Matters (and Why It Might Not)
The implications of this research, if taken at face value, could suggest that current embedding-based retrieval methods have a ceiling on their performance, particularly for tasks that deviate from expected data patterns. The paper posits that as AI systems are pushed to handle more nuanced and complex queries, the limitations of fixed-dimension embeddings will become more apparent.
However, the analysis of the paper strongly emphasizes that these limitations are primarily theoretical and apply to scenarios involving ‘random data.’ In practical AI applications, data typically possesses inherent structure. For instance, documents about ‘Paris’ and ‘Metro’ are often related due to the real-world structure of cities having transportation systems. Machine learning, including embedding generation, thrives on learning and exploiting this structure.
The speaker argues that the paper’s focus on arbitrary combinations misses the point of why embedding-based retrieval is successful. Its success stems precisely from its ability to capture and leverage the *structure* present in natural language and data.
When data has structure, embeddings can provide a compressed, generalizable representation. If one needs to represent purely arbitrary combinations, traditional sparse methods like BM25 (which essentially act as sophisticated keyword matching) might be more appropriate, albeit less nuanced for semantic similarity.
Experimental Validation and Unexpected Results
To support their theoretical claims, the researchers conducted experiments. They constructed datasets designed to test the limits of embedding retrieval, specifically looking at the ability to retrieve arbitrary pairs of items. They then attempted to optimize embedding vectors directly (rather than training a model) to see how many data points could be represented within a given embedding dimension before retrieval accuracy degraded.
Surprisingly, even with adversarially constructed datasets designed to break embeddings, the results showed a remarkable capacity. For instance, with 1,000-dimensional embeddings, the system could still accurately represent arbitrary pairs from a set of up to 4 million elements. This suggests that even at the theoretical edge, current embedding dimensions offer substantial representational power.
The Takeaway: Managing Expectations
While the paper rigorously proves that embedding-based retrieval cannot perfectly capture *all* arbitrary combinations of data, especially in a theoretical vacuum, its practical impact is debated. The analysis suggests that the research might be overstating the problem for real-world applications where data structure is the norm.
The core message for practitioners is a reminder to manage expectations. Embedding models are tools designed to leverage data structure for semantic understanding.
They are not magic bullets capable of retrieving any conceivable combination without regard for the underlying patterns. The paper is a useful, albeit theoretical, reminder of the trade-offs involved in dimensionality reduction and information compression inherent in machine learning models.
Source: [Paper Analysis] On the Theoretical Limitations of Embedding-Based Retrieval (Warning: Rant) (YouTube)