AI Models’ Inner Workings Revealed by New Analysis
Researchers are peeling back the layers of artificial intelligence, offering unprecedented insights into how large language models (LLMs) like Anthropic’s Claude 3.5 Haiku perform complex tasks. A recent deep dive, building upon prior work, utilizes a technique called “attribution graphs” to visualize the decision-making processes within these sophisticated AI systems. This method, detailed in Anthropic’s research, employs a “replacement model” trained to mimic the original transformer architecture but with modifications that allow for more granular analysis.
Decoding AI: The Power of Attribution Graphs
The core of this investigative technique lies in creating a “replacement model.” Unlike standard transformer models, this specialized version allows for cross-layer connections, meaning any part of the model can receive input from all preceding layers. It’s trained to be highly sparse, penalizing unnecessary complexity.
The goal is to create a model that not only replicates the output of the original AI but also its intermediate processing, yet is more amenable to analysis. This allows researchers to trace the flow of information, identify activated features, and pinpoint which elements in the training data influenced specific outputs.
How AI Tackles Addition: Not So Simple
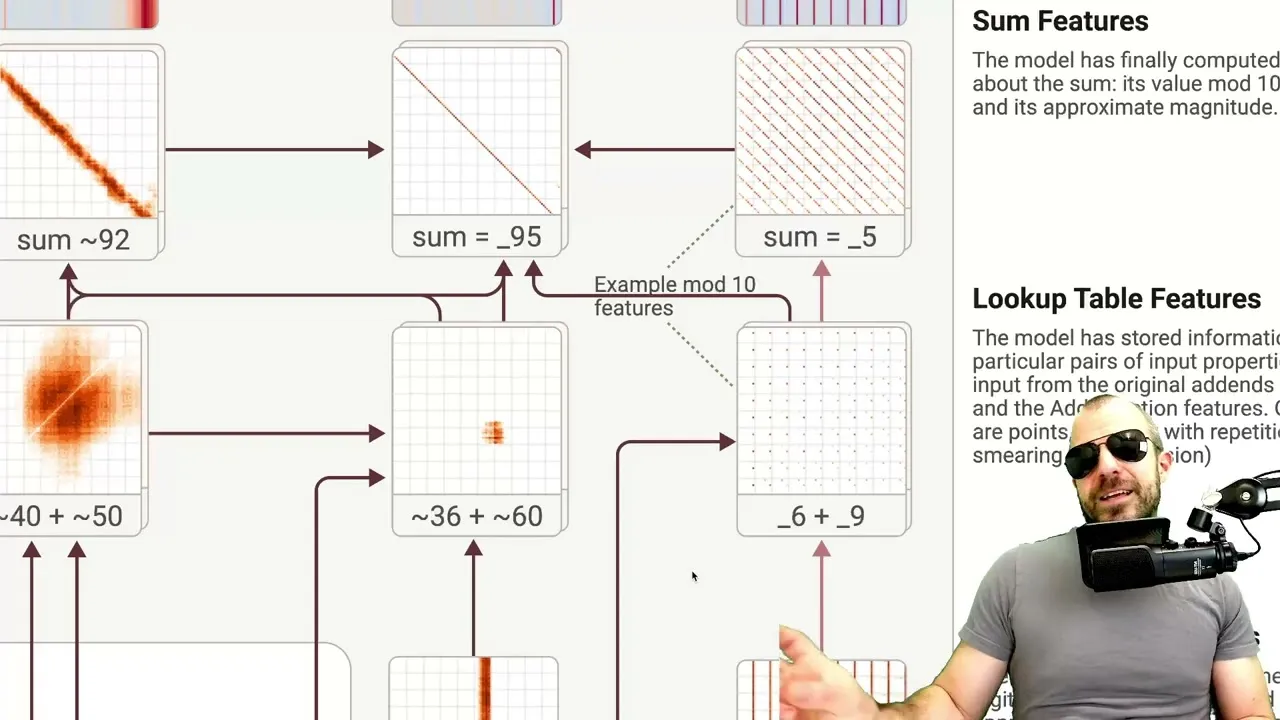
One of the most intriguing revelations from the analysis concerns how LLMs perform basic arithmetic, such as adding two-digit numbers. Instead of a single, linear computational pathway, the model appears to activate multiple parallel features. For instance, when adding 36 + 59, the model doesn’t just see “36” and “59.” It activates features related to the numbers themselves (e.g., “around 30,” “ends in six”) and then, upon encountering the equals sign, triggers a cascade of computation-specific features.
These features aren’t always precise; some estimate ranges (e.g., “adding 40 and 50-ish”), while others focus on specific aspects like the units digit or modulus arithmetic (e.g., “adding something that ends in nine”). The model then combines these approximate computations, often leveraging features that predict the likely outcome or the final digit, to arrive at the answer.
This contrasts sharply with the model’s own explanation, which often mimics human-like step-by-step arithmetic, suggesting a potential disconnect between how LLMs *explain* their reasoning and how they *arrive* at an answer. Researchers caution that the replacement model’s interpretation might not perfectly reflect the original transformer’s internal process, but it offers a compelling glimpse into potential shortcut-like mechanisms.
Generalization and the Roots of Mathematical Ability
The analysis also touches upon how LLMs generalize their mathematical capabilities. It appears that the features enabling arithmetic aren’t confined to explicit math problems.
They can be activated in contexts like astronomical measurements or cost tables, indicating that models learn mathematical operations implicitly from vast amounts of data. However, a significant challenge remains: understanding precisely how models recognize when mathematical operations are needed in the first place, even when the prompt doesn’t explicitly ask for calculation.
AI in Medical Diagnosis: Internal Representations
The research extends to the realm of medical diagnosis. When presented with a patient’s symptoms and asked for the most pertinent follow-up question, the AI, exemplified by Claude 3.5 Haiku, correctly identifies a key diagnostic indicator (e.g., visual disturbances for a patient with pre-eclampsia symptoms). The attribution graphs reveal that the model doesn’t just directly link symptoms to diagnostic criteria.
Instead, it appears to form internal representations of potential diagnoses. For instance, symptoms might activate features representing “pre-eclampsia,” which then inform the choice of the next diagnostic question.
This suggests that LLMs can construct and utilize abstract concepts internally, enabling more complex reasoning than a simple input-output mapping might imply. This internal conceptualization is crucial for multi-step reasoning, though the limited layers in transformer models can constrain the depth of subsequent computations.
Understanding Hallucinations and Refusals
A significant portion of the analysis digs into phenomena like hallucinations (generating false information) and refusals (declining to answer). The researchers propose that these behaviors can be understood through the lens of “default circuits.” In essence, models have an always-active circuit that prompts them to decline answering or state they don’t know. When presented with information it recognizes (like a well-known person), the model activates features that inhibit this default circuit, allowing it to respond.
Hallucinations, in this view, can arise from a misfiring of this inhibitory mechanism. Conversely, refusals, such as declining to provide instructions for mixing bleach and ammonia due to safety concerns, are attributed to specific features activated by the combination of keywords.
These safety mechanisms, while crucial, are described as surface-level correlations learned during fine-tuning rather than deep ethical reasoning. This simplistic correlation-based approach, the researchers suggest, makes these refusal mechanisms susceptible to “jailbreaking” attempts, where users craft prompts to circumvent the safety filters.
The Nature of AI Learning
Ultimately, Anthropic’s “biology of a large language model” study, as interpreted by the analysis, suggests that many advanced AI behaviors—from arithmetic to diagnosis and safety protocols—are sophisticated manifestations of underlying training processes. While the language used to describe these capabilities often evokes human-like cognition (thinking, planning, understanding), the attribution graphs point towards complex pattern matching, feature activation, and approximation. The research underscores that “training works” and that LLMs are exceptionally adept at learning from vast datasets, but the precise mechanisms and the extent of true “understanding” remain areas of active investigation.
Source: On the Biology of a Large Language Model (Part 2) (YouTube)



