Nvidia’s TiDAR Blends AI Models for Faster Text Generation
Researchers at Nvidia have developed a new approach called TiDAR, which combines two different types of artificial intelligence models to speed up the process of generating text. This innovation aims to make large language models (LLMs) more efficient without sacrificing the quality of the output.
The Problem: Underused GPUs
Large language models, like those powering chatbots, often work by predicting one word, or ‘token,’ at a time. This step-by-step method, known as autoregressive decoding, produces high-quality, coherent text. However, it can be slow because the graphics processing units (GPUs) used for these calculations are not always fully busy. They often wait for data, becoming ‘memory bound’ rather than using all their processing power.
The Goal: Using Idle Power
The TiDAR paper asks: how can we use this extra, unused GPU power intelligently? The goal is to get a speed boost without the usual trade-offs seen in other speed-up techniques. TiDAR offers a way to do this, essentially using a bit more electricity for computation without complex compromises.
Understanding the Building Blocks
To understand TiDAR, it’s helpful to know about the two main AI model types it combines:
- Autoregressive Models: These models, like GPT, generate text one token after another. They look at all the words that came before (the ‘prefix’ or ‘prompt’) to predict the very next word. This sequential process ensures that the text flows logically and makes sense. However, generating text this way can be slow because each word depends on the one before it.
- Diffusion Language Models: These models can generate many tokens at once. Instead of predicting one word after another, they predict all the future words simultaneously. While faster, this method often results in lower quality because it doesn’t consider how the predicted words interact with each other. It generates ‘marginal distributions’ for each token, meaning it predicts each word in isolation without fully understanding their relationships.
The Trade-off: Quality vs. Speed
Autoregressive models offer better quality because they are more principled, building text step-by-step. Diffusion models are faster because they can work on multiple parts at once. The challenge has been to get the speed of diffusion models without losing the quality of autoregressive models.
Speculative Decoding: A Hint of the Future
Before TiDAR, techniques like ‘speculative decoding’ tried to speed things up. Imagine you have a helper model that makes a quick guess at the next few words. Then, the main, powerful model checks if that guess is correct. If the guess is right, you’ve saved time because the powerful model only had to verify, not generate from scratch. If the guess is wrong, you discard it and the powerful model generates the correct word. This works well if the helper model is accurate and fast, but if it’s slow or often wrong, it can actually slow things down.
TiDAR’s Hybrid Approach
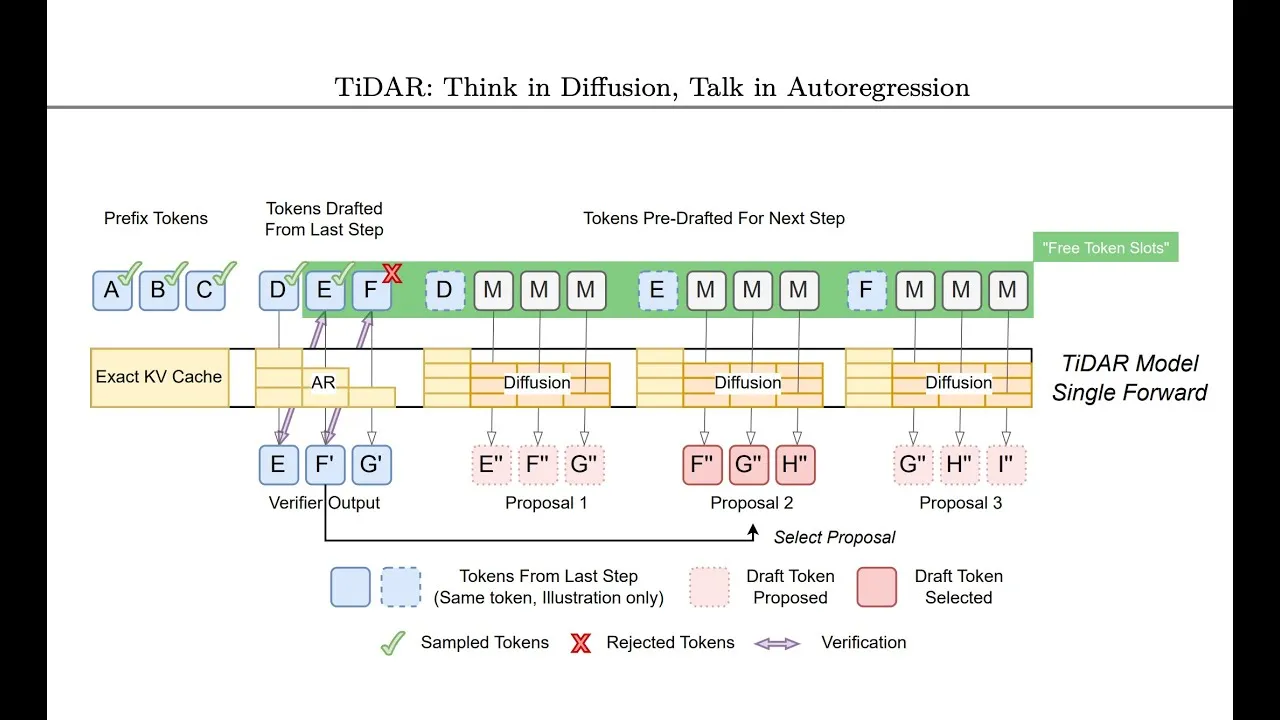
TiDAR uses a clever hybrid architecture. It allows for parallel token computation, similar to diffusion models, but still samples text in a way that maintains the high quality of autoregressive models. It does this by using the unused GPU capacity.
Here’s how it works:
- Drafting with Diffusion: At each step, while the main autoregressive model is busy checking the current sequence, TiDAR uses the spare GPU power to ‘draft’ potential future tokens using a diffusion model. This draft is essentially a set of likely next words.
- Autoregressive Checking: The autoregressive model then checks this draft. It uses a process called ‘rejection sampling’ to see if the drafted tokens match what it would have generated step-by-step.
- Parallel Processing: The key is that this checking and drafting happen at the same time within a single ‘forward pass’ of the GPU. If the autoregressive model accepts the drafted tokens, multiple words can be generated in one go, significantly speeding up the process.
- Handling Rejections: If the autoregressive model rejects some of the drafted tokens (meaning they wouldn’t have been the next logical words), TiDAR doesn’t waste the effort. It can use the spare capacity to immediately start drafting for the *next* possible sequence of events. It essentially prepares drafts for all likely outcomes, ensuring there’s always a draft ready for the next step, no matter what the current step decides.
Why This Matters
This approach is significant because it offers a way to make LLMs much faster without compromising the quality of their output. Faster generation means:
- More Responsive Chatbots: Users will experience quicker replies from AI assistants.
- Efficient Content Creation: Writers and creators can generate text drafts more rapidly.
- Lower Costs: More efficient use of GPU resources could lead to reduced operational costs for AI services.
- Advancing AI Capabilities: By solving efficiency bottlenecks, researchers can focus on building even more powerful and complex AI systems.
Availability and Future
TiDAR is presented in a research paper by Nvidia. Specific product integrations, pricing, or availability details are not yet announced, but this research points towards future improvements in how we interact with and utilize AI language models.
Source: TiDAR: Think in Diffusion, Talk in Autoregression (Paper Analysis) (YouTube)



