AI Ditches Tokens for Patches in New Transformer Model
A groundbreaking research paper introduces the Byte Latent Transformer (BLT), a novel architecture that challenges the long-standing reliance on traditional tokenization in Large Language Models (LLMs). Instead of breaking text into fixed, pre-defined tokens, BLT utilizes dynamic “patches” of bytes, a shift that the researchers claim leads to significantly better scaling properties. This innovation could pave the way for more efficient and capable AI models.
The Problem with Traditional Tokenization
For years, LLMs have relied on tokenization to process text. Common methods like Byte Pair Encoding (BPE) or WordPiece break down text into smaller units – words, sub-words, or even characters. While effective, this approach has inherent limitations:
- Fixed Vocabulary Issues: Tokenizers are trained on a corpus, creating a fixed vocabulary. This can lead to “out-of-vocabulary” (OOV) words, where unseen words are either poorly represented or broken down into less meaningful pieces.
- Loss of Granularity: Tokenization can obscure the underlying structure of data. For instance, a number like ‘2568’ might be tokenized into ‘256’ and ‘8’, losing the numerical relationship for the model.
- Sequence Length: While better than character-level processing, tokenization can still result in long sequences, especially for languages with complex scripts or when dealing with code, which quadratically impacts Transformer efficiency.
- Inefficiency for Certain Tasks: Tasks requiring fine-grained character or byte-level understanding, like spelling correction or certain translation tasks, can be hindered by the abstraction of tokenization.
The BLT paper argues that these limitations, coupled with the need to store embeddings for every token in a potentially massive vocabulary, hinder optimal scaling. They propose moving away from this fixed, vocabulary-based approach.
Introducing the Byte Latent Transformer (BLT)
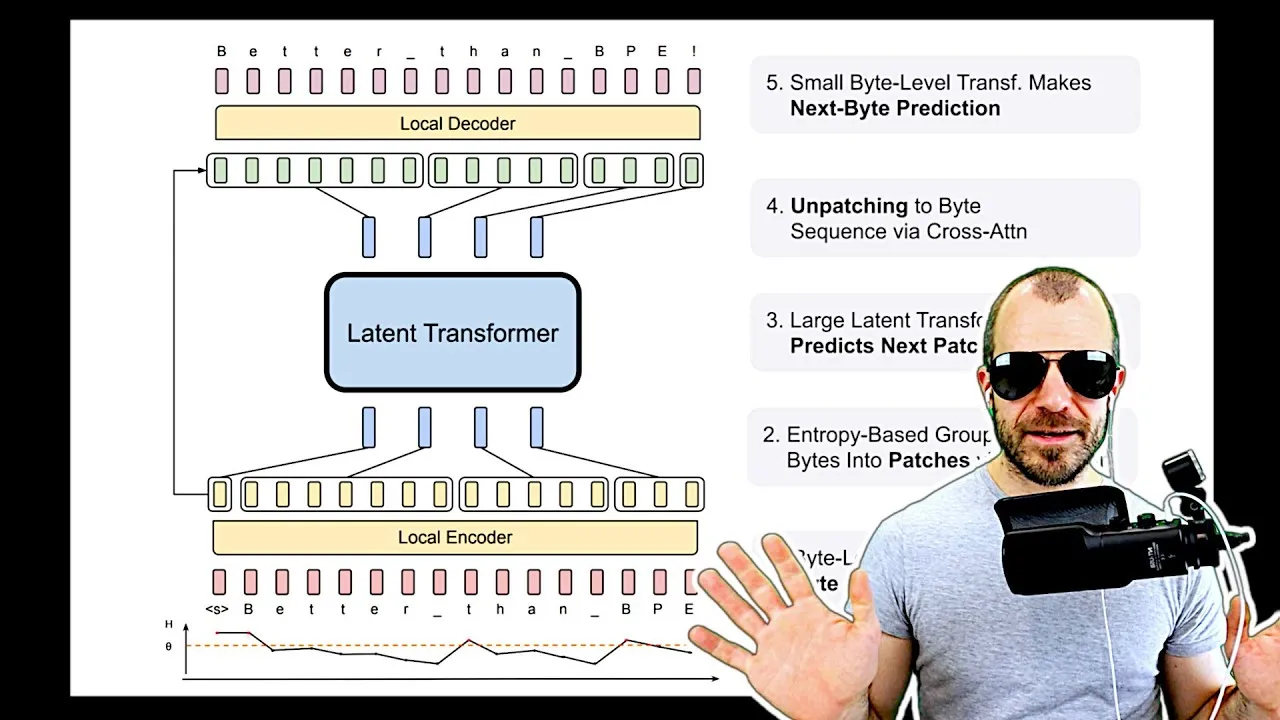
The core innovation of BLT lies in its dynamic “patching” mechanism. Instead of relying on a pre-defined vocabulary, BLT processes text by grouping sequences of bytes into variable-sized “patches.” These patches then serve as the input to a core Transformer model, which the researchers call the “latent Transformer.” This architecture is described as a two-tier system:
- Inner Layer (Latent Transformer): This is a standard autoregressive LLM Transformer that operates on “patch embeddings.” Unlike traditional models that predict the next token, BLT’s inner layer predicts the next patch embedding.
- Outer Layer (Patching Mechanism): This component dynamically groups bytes into patches and generates embeddings for them. This involves a local encoder that takes byte sequences and produces patch embeddings, and a local decoder that can reconstruct the bytes from a patch embedding.
The key idea is that by using larger, dynamically determined patches, the model can achieve better scaling for the same amount of computational resources (training FLOPs). The paper presents experimental results showing that BLT models, when matched for training FLOPs, outperform traditionally tokenized models beyond a certain threshold.
How Patching Works: Entropy-Based Grouping
The dynamic creation of patches is guided by an entropy-based grouping mechanism. A small, auxiliary byte-level LLM is trained to predict the next byte. If the prediction entropy is high (meaning the model is uncertain about the next byte), it signals a potential split point, forming a new patch boundary. Conversely, low entropy suggests a predictable sequence, which is kept together within a patch.
This approach has several advantages:
- Dynamic Segmentation: Patches are not fixed but adapt to the content, grouping predictable sequences and splitting uncertain ones.
- Reduced OOV Issues: By operating closer to the byte level, BLT inherently avoids the OOV problem associated with fixed token vocabularies.
- Flexible Input Size: The size of patches can be adjusted, allowing for a trade-off between the frequency of running the inner latent Transformer and the complexity of the patches. Larger patches mean fewer calls to the computationally intensive inner Transformer.
The paper also details how the local encoder and decoder work. The local encoder takes byte embeddings (potentially augmented with n-gram information for context) and aggregates them into a patch embedding. The local decoder then uses this patch embedding, along with a global signal from the latent Transformer, to generate the sequence of bytes within that patch. The stopping point for the decoder is also determined by the entropy of the auxiliary byte-level LLM’s predictions.
Experimental Results and Performance
The researchers compared BLT against established models like Llama 2 and Llama 3. Key findings include:
- Improved Scaling: BLT demonstrated better scaling properties, achieving comparable performance to Llama models with larger average patch sizes (6-8 bytes) compared to the average token sizes of Llama 2 (3.7 bytes) and Llama 3 (4.4 bytes).
- Enhanced Performance on Specific Tasks: BLT showed superior performance on tasks requiring fine-grained character or spelling awareness, such as spelling correction, outperforming Llama models.
- Better Translation for Under-represented Languages: The approach proved beneficial for translating languages that are typically tokenized in non-standard ways.
While BLT shows promising scaling benefits, the paper acknowledges that raw runtime performance currently lags behind highly optimized traditional tokenization methods. This is attributed to the extensive optimization efforts over years for existing LLM architectures. However, by matching models on FLOPs, the study provides a strong basis for comparing fundamental architectural efficiency.
Why This Matters
The Byte Latent Transformer represents a significant departure from conventional LLM architectures. By moving beyond fixed tokenization, BLT offers a potential path to:
- More Efficient Training: Better scaling could mean achieving higher performance with the same or fewer computational resources.
- Improved Handling of Diverse Data: The dynamic patching approach may be more robust to variations in text, including code, specialized jargon, and languages with complex structures.
- Enhanced Capabilities: Tasks that benefit from a deeper understanding of sub-token information, like precise editing or nuanced translation, could see substantial improvements.
While the technology is still in its early stages and requires further optimization for real-world deployment, the BLT paper lays a compelling theoretical and experimental foundation for a new generation of AI models that process information in a more flexible and scalable manner.
Source: Byte Latent Transformer: Patches Scale Better Than Tokens (Paper Explained) (YouTube)