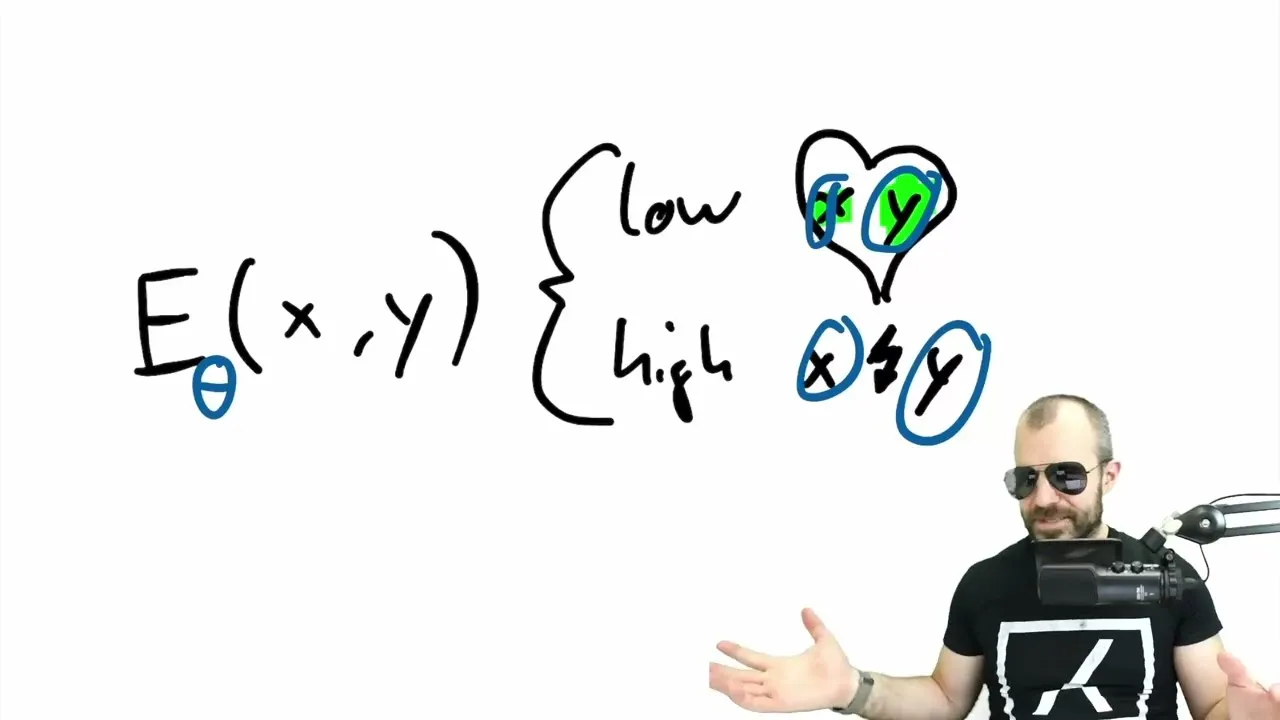
AI Rethinks Thinking: Energy-Based Transformers Emerge
A novel research direction is challenging the fundamental way artificial intelligence models learn and process information. By merging the established power of transformer architectures with the principles of energy-based models (EBMs), researchers are proposing a new paradigm for AI that aims to enable more scalable and sophisticated forms of ‘thinking’ – particularly System 2 thinking, characterized by slow, deliberate reasoning.
From System 1 to System 2: A New Frontier for AI
Most current machine learning models, including many advanced language models, operate largely within the realm of System 1 thinking. This is akin to rapid, intuitive, and often subconscious decision-making. Think of the effortless act of reaching for a banana – your brain doesn’t consciously break down the physics of movement or muscle coordination. This is fast, efficient, and the default for many daily tasks.
System 2 thinking, in contrast, is the deliberate, analytical, and time-consuming process we engage in when faced with complex problems or novel situations. It involves working through logical steps, evaluating options, and arriving at a conclusion. While some argue that deep, multi-layered transformers might exhibit rudimentary forms of this through their sequential processing, the researchers behind this new work posit that true System 2 capabilities in AI require a different approach.
The core question driving this research is ambitious: Can AI models learn to perform System 2 thinking purely through unsupervised learning, without explicit human supervision or predefined rewards? This would unlock the potential for AI to generalize reasoning abilities across any problem, any data modality, and reduce reliance on domain-specific training often seen with methods like reinforcement learning for tasks like math or coding.
Energy-Based Models Meet Transformers
The proposed solution lies in combining energy-based models with transformers. Energy-based models work by defining an ‘energy function’ that assigns a low energy value to compatible inputs and outputs, and a high energy value to incompatible ones. In essence, the model learns what ‘fits’ together.
Traditionally, EBMs have faced challenges with parallelization, stability, and scalability. Transformers, on the other hand, excel in these very areas, offering robust architectures for handling sequential data and enabling massive parallel computation.
The synergy is compelling: by implementing EBM principles within a transformer architecture, dubbed Energy-Based Transformers (EBTs), researchers aim to leverage the strengths of both. This new architecture is explored through a learning paradigm designed to foster these advanced reasoning capabilities.
Key Facets of ‘Thinking’ in EBTs
The researchers identify three key facets of System 2 thinking that their EBTs naturally embody:
- Dynamic Allocation of Computation: Unlike standard models that perform a fixed forward pass, EBTs allow for more computational effort during inference. By running multiple forward passes, the model can refine its predictions and potentially achieve greater accuracy, akin to how humans might revisit a problem to improve their solution.
- Modeling Uncertainty: Real-world scenarios are often unpredictable. EBTs, inherent to EBMs, can model uncertainty in their predictions. This is crucial for cautious decision-making, allowing the AI to express when it’s less confident about an outcome, much like a human might hesitate when faced with ambiguity.
- Verification of Predictions: EBTs possess an intrinsic ability to ‘judge’ their own predictions. This is similar to the discriminator in Generative Adversarial Networks (GANs), where a component assesses the quality or plausibility of an output. This self-assessment capability is vital for refining reasoning processes.
How EBTs ‘Think’ at Inference
The inference process in EBTs is fundamentally different from a single forward pass. Instead of directly outputting a prediction, an EBT refines an initial, often random, distribution over possible outputs. This refinement is an iterative optimization process guided by the learned energy function.
Imagine predicting the next word in a sentence. An EBT doesn’t just pick one word. It starts with a broad spectrum of possibilities and, through repeated computations (gradient descent on the energy function), gradually narrows down and shapes this distribution until it converges on a more confident and accurate prediction. The depth of this iterative process can be controlled, allowing for a trade-off between computational cost and prediction quality.
This iterative refinement, where more computation can lead to better results, is what the researchers equate to a form of ‘thinking’. It’s not just about generating an answer, but about an optimization procedure guided by a learned verifier that evaluates the compatibility between input context and candidate predictions.
Training for Scalable Reasoning
Training these EBTs presents unique challenges. A naive approach can lead to a highly irregular and difficult-to-navigate ‘energy landscape’. To address this, the researchers employ several techniques:
- Contrastive Training: Initially, EBMs can be trained using contrastive methods, where the model learns to assign lower energy to correct input-output pairs and higher energy to incorrect ones.
- Backpropagating Through Optimization: A more advanced training method involves backpropagating the loss through the inference-time optimization steps. This requires computing gradients of gradients (second-order derivatives), which, while computationally intensive, can be managed efficiently. The training objective is to find outputs that are good *after* the iterative refinement process.
- Regularization Techniques: To ensure a smoother and more generalizable energy landscape, techniques like using a replay buffer, adding noise to gradient steps during training, and randomizing the gradient step size and number of optimization steps are employed. These methods help the model generalize better to unseen data and become more robust to variations in computational effort during inference.
Why This Matters
The development of Energy-Based Transformers represents a significant step towards building AI systems that can reason more deliberately and adaptively. The ability to perform unsupervised learning for complex thinking processes could:
- Enhance AI Robustness: By modeling uncertainty, AI can become more cautious and reliable in critical applications.
- Improve Generalization: Moving beyond task-specific rewards allows AI to tackle a wider range of problems without extensive retraining.
- Unlock New Applications: More sophisticated reasoning could lead to breakthroughs in scientific discovery, complex problem-solving, and human-AI collaboration.
While the current experimental results are on smaller datasets, the observed scaling trends suggest that EBTs hold considerable promise for large-scale applications. This research opens a new avenue for exploring more human-like cognitive processes within artificial intelligence.
Source: Energy-Based Transformers are Scalable Learners and Thinkers (Paper Review) (YouTube)



