Anthropic Unlocks LLM Secrets with Circuit Tracing
In the rapidly evolving landscape of artificial intelligence, understanding the inner workings of large language models (LLMs) has become a paramount challenge. Unlike traditional machine learning models, where logic was explicit and traceable, LLMs exhibit emergent capabilities that are not directly programmed. This has led researchers to adopt a more observational, almost biological approach to deciphering their internal processes. A recent blog post series from Anthropic, titled “On the Biology of a Large Language Model,” delves into this complex issue, introducing a novel technique called circuit tracing to illuminate how these powerful models arrive at their outputs.
The “Biology” of LLMs: A New Paradigm
Historically, machine learning models like support vector machines were designed with clear, understandable mechanisms. Developers knew precisely how inputs were processed to produce outputs. However, the advent of LLMs has shifted this paradigm. These models are trained on vast datasets, and their remarkable abilities—from writing poetry to performing arithmetic—emerge organically rather than through explicit coding. This leaves researchers in a position akin to biologists, observing and experimenting to understand the organism’s behavior.
Anthropic’s work tackles this by investing resources into methods that can peer inside the “black box” of LLMs. The core of their investigation lies in a technique they call circuit tracing, which aims to explain model behavior by identifying activated features and understanding how they contribute to the final output. While the author of the original post expresses some reservations about Anthropic’s framing, the methodology itself offers a compelling avenue for interpretability.
Circuit Tracing: Peering Inside the Transformer
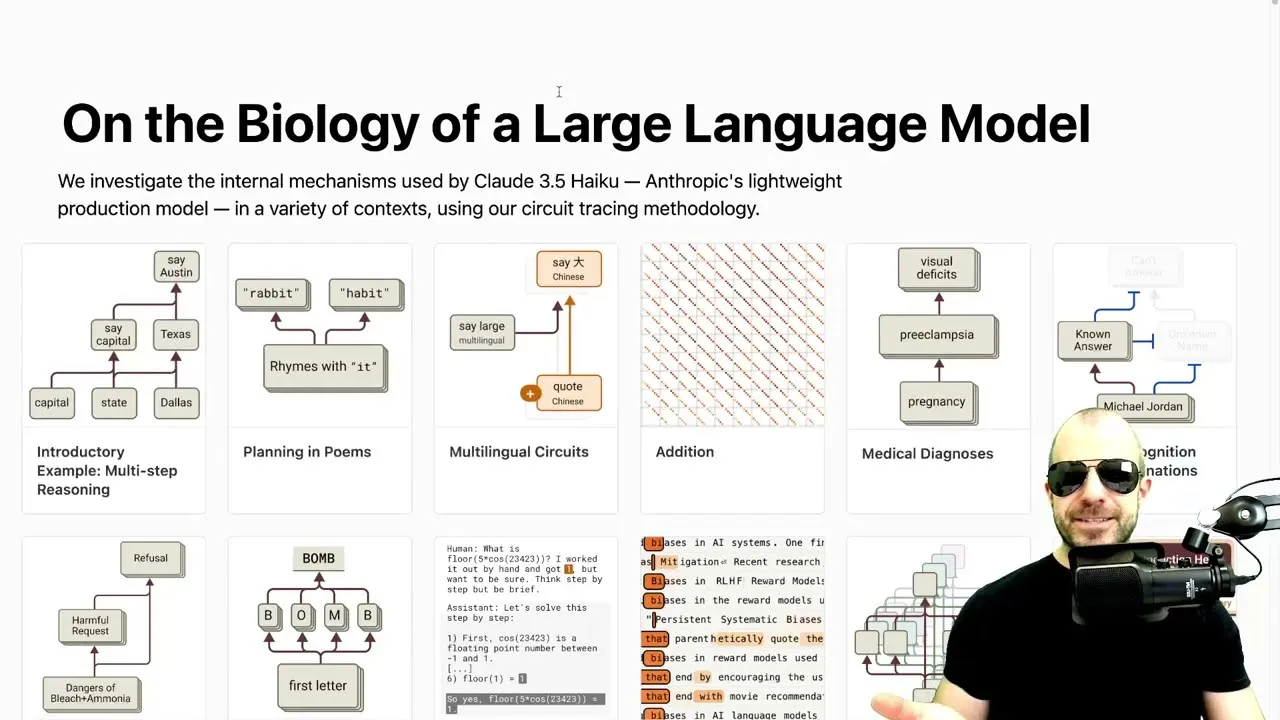
The foundation of Anthropic’s approach is a technique called circuit tracing, which is detailed in a companion blog post. This method involves training a more interpretable “replacement model” that mimics the behavior of the original transformer model. This replacement model, often a type of architecture called a transcoder, provides clearer, more interpretable intermediate signals.
Transcoders are designed to replicate the outputs of each layer of a transformer model. Crucially, they differ from standard transformer layers in a few key ways:
- Cross-Layer Connectivity: Unlike a standard transformer’s MLP (multi-layer perceptron), which only receives input from the immediately preceding layer, a transcoder at any given layer can access the outputs of *all* previous layers. This allows the model to directly retrieve information from earlier stages of processing, making the flow of information more transparent.
- Sparsity Regularization: Transcoders are trained with a sparsity penalty. This encourages features within the model to become more independent and represent distinct concepts rather than overlapping information. The goal is to activate as few features as possible for any given task, making it easier to pinpoint the function of each activated feature.
- Linearity: The training process encourages features to contribute in a more linear fashion. This means the output can often be represented as a sum of specific feature contributions, simplifying the analysis of how different components interact.
These design choices result in an interpretable output, often visualized as “attribution graphs.” These graphs map which features are activated by specific inputs and how these activations lead to particular outputs. However, the author notes that these transcoder models can be computationally more intensive to train, less stable, and may lead to a loss in performance compared to standard transformers. The key question remains: do these interpretable models accurately reflect the internal processes of the original transformer, or do they lead to misleading conclusions?
Intervention Experiments: Testing the Tracing
To validate their findings, Anthropic employs intervention experiments. By selectively suppressing or inverting the signals of specific features within their replacement model, they observe the impact on the final output. If the model’s internal logic is accurately captured, manipulating these features should predictably alter the output.
For instance, in a multi-step reasoning task like identifying the capital of the state containing Dallas (Austin), intervention experiments showed that suppressing features related to “capital” or “Texas” directly affected the model’s ability to output “Austin.” Similarly, substituting “California features” for “Texas features” in a prompt about Dallas successfully changed the output to Sacramento. These experiments suggest that the circuit tracing method, while perhaps not a perfect mirror, provides valuable insights into the model’s decision-making process.
Unpacking Reasoning and Rhyme Schemes
The blog post highlights two key examples of circuit tracing in action:
- Multi-Step Reasoning: For a prompt requiring two steps of deduction (e.g., finding the state Dallas is in, then its capital), the attribution graphs revealed that the model does appear to materialize intermediate steps. Features related to “Dallas” activate “Texas”-related features, which then contribute to activating “Austin.” However, the analysis also shows a significant overlap with direct “shortcut” connections, suggesting that the model relies on both learned reasoning paths and strong statistical word associations. This overlap might explain phenomena like hallucinations when statistical associations conflict with logical deduction.
- Poetry and Rhyme Planning: When generating poetry, particularly rhyming couplets, circuit tracing indicates that LLMs do not simply improvise at the end of a line. Instead, they appear to plan rhymes in advance. At the point of a new line character, features related to rhyming with the previous line’s ending word are activated. The model internally represents potential rhyming words (like “rabbit” or “habit”) and concepts, allowing it to semantically construct a line that fits the rhyme scheme. Intervention experiments, such as suppressing rhyming features, led to outputs that lacked rhyme, confirming the model’s planning capabilities. Interestingly, the analysis also suggests that special tokens like newlines and end-of-sentence markers play a crucial role in triggering this planning behavior, as they offer greater freedom from immediate grammatical constraints.
Why This Matters
Anthropic’s circuit tracing technique represents a significant step towards demystifying LLMs. By providing a method to visualize and probe the internal mechanisms of these complex models, it offers several potential benefits:
- Improved Interpretability: Understanding *why* an LLM produces a certain output is crucial for trust, debugging, and ethical deployment. Circuit tracing offers a more concrete way to achieve this than previous methods.
- Enhanced Model Development: Insights into how LLMs handle reasoning, planning, and concept representation can guide the development of more capable and reliable AI systems. Identifying where models rely on spurious correlations versus genuine reasoning could lead to architectures that are less prone to errors and hallucinations.
- Unlocking New Capabilities: By understanding the planning mechanisms in poetry generation, for example, developers might find ways to imbue LLMs with more sophisticated creative or strategic planning abilities in other domains.
While the accuracy and completeness of circuit tracing as a representation of true LLM internals are still subjects of debate, Anthropic’s work provides a powerful new lens through which to examine the ‘biology’ of artificial intelligence, moving us closer to truly understanding the intelligence we are building.
Source: On the Biology of a Large Language Model (Part 1) (YouTube)