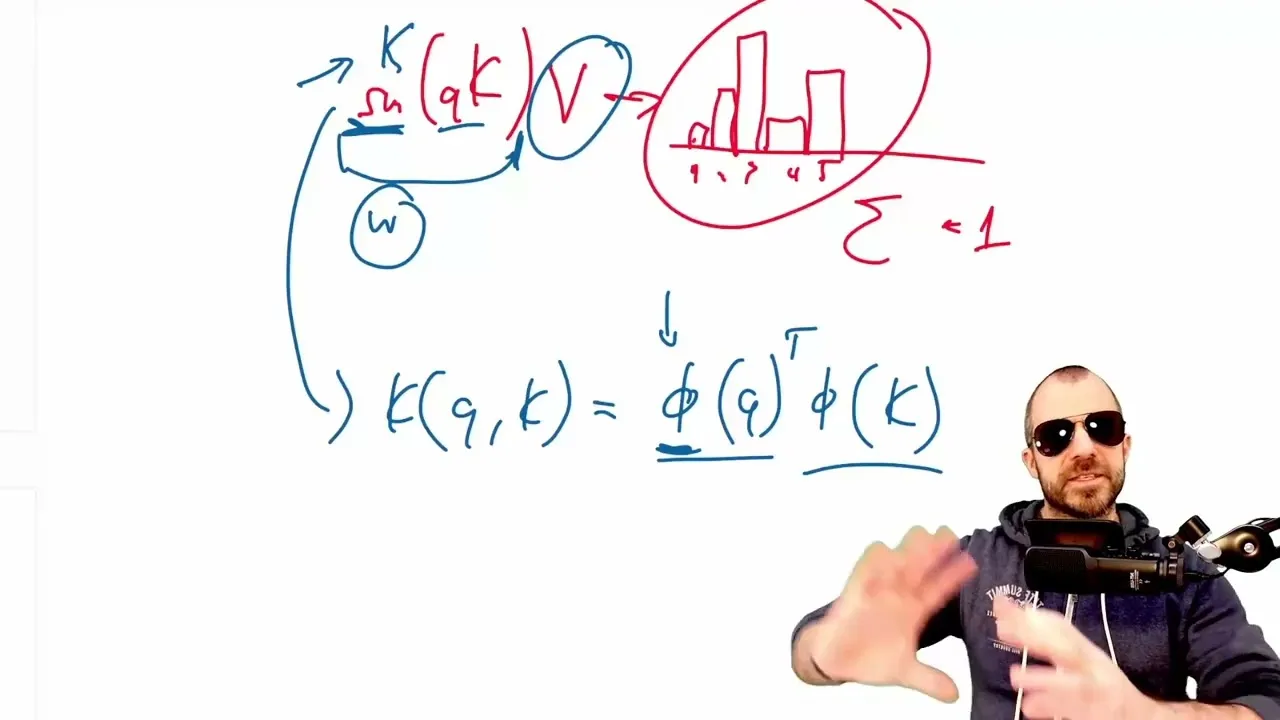
Google Research Unveils Titans: A New Approach to AI Memory
Google Research has introduced a novel AI architecture, dubbed Titans, designed to overcome the inherent context window limitations of current transformer models. Published as part of the NeurIPS proceedings, the research proposes a system that can learn to memorize and recall information beyond its immediate processing window, effectively extending its memory at test time.
The Context Window Conundrum
Modern AI models, particularly those based on the transformer architecture, excel at processing sequential data like text. However, they are constrained by a fixed ‘context window’ – the amount of data the model can consider at any given moment. For tasks involving very long sequences, such as video analysis or extensive document comprehension, this limitation becomes a significant bottleneck. Traditional transformers can only attend to information within this window, making it impossible to connect distant pieces of information without specialized techniques.
Researchers have explored various methods to address this, including:
- Recurrent Approaches: Early transformer variants and some RNN-like structures attempted to pass compressed information (like hidden states) from one processing chunk to the next. This allowed a form of memory but often resulted in information loss due to compression.
- Linear Transformers: These models aim to simplify the attention mechanism, often by using kernel functions. The idea is to reformulate the attention calculation to avoid the quadratic complexity of standard transformers, enabling more efficient processing of longer sequences. However, the paper notes that these linear approximations can sometimes lead to performance degradation, effectively turning the model into a form of linear recurrent network that struggles to compress long contexts effectively.
Titans’ Novel Memory Mechanism
The core innovation of Titans lies in its approach to memory. Instead of relying on fixed-size states or linear approximations, Titans treats memory as a dynamic neural network that is updated and trained on-the-fly during inference (at test time).
Here’s how it works:
- Dynamic Memory Network: The memory component is essentially a small neural network (an MLP in the described architecture). This network is responsible for storing and retrieving information from the past.
- Test-Time Training: As the model processes a sequence, it continuously updates the parameters of this memory network. This process is akin to in-context learning or fine-tuning, but it happens during the actual prediction phase. The goal is for the memory network to learn associations between ‘keys’ (representing specific pieces of information) and ‘values’ (the associated data).
- Surprise-Based Updates: The paper frames the memory update process using a concept of ‘surprise.’ The memory network is trained to associate keys with values, with a loss function that encourages learning from unexpected or novel information. This is likened to gradient descent with momentum, where surprising events lead to parameter updates.
- Retrieval: When processing new data, the model can query this memory network. The network, having learned from past data, can then return relevant information, effectively allowing the model to ‘remember’ details from far beyond its standard context window.
Rethinking ‘Memory’ and ‘Parameters’
The authors of the paper interpret various AI architectures through the lens of memory. They suggest that even standard transformers have a form of memory in their keys and values, and RNNs use their hidden state as memory. However, they argue that these are often limited by their fixed or linear nature.
The Titans paper also introduces the concept of a ‘persistent task memory,’ which the authors equate to learned parameters that are independent of the input data but specific to the task. Critics, however, point out that this ‘persistent memory’ is functionally similar to existing techniques like prefix tuning or simply refers to learned parameters within the model, raising questions about the novelty of this framing.
A point of contention raised by the analysis is the paper’s strong emphasis on the limitations of ‘vector-valued’ or ‘matrix-valued’ memories compared to their proposed ‘neural network-based memory.’ The analysis suggests that the distinction might be overstated, as complex retrieval and storage mechanisms can be implemented with simple memory structures, and vice-versa, leading to equivalent capabilities.
Why This Matters
The ability for AI models to effectively memorize and recall information over extended periods is crucial for developing more capable and human-like AI. Tasks requiring a deep understanding of long narratives, complex dialogues, or evolving situations could see significant improvements.
Titans represents a promising direction in addressing the fundamental challenge of context length in AI. By enabling models to learn and adapt their memory at test time, such architectures could unlock new levels of performance in a wide range of applications, moving beyond the current limitations of fixed context windows.
While the paper is praised for its core idea and experimental results, the analysis highlights a potential tendency to reframe existing concepts with new terminology, particularly around the nature of memory and parameters.
Source: Titans: Learning to Memorize at Test Time (Paper Analysis) (YouTube)